
1. 변환기의 필요성
프로젝트를 진행하다보면 가장 많은 시간이 걸리고 노력이 필요한 부분이 데이터 전처리 과정일 것입니다. 처음 프로젝트를 할때는 경험이 부족해 필요할 때마다 데이터를 변환하다보니 테스트를 위해 분류해둔 테스트 데이터를 변환하기위해 같은 작업을 반복하느라 시간을 낭비하는 경우가 많았습니다.
만약 나만의 변환기를 만들어 둔다면 이러한 문제를 해결하는데 도움이 될 것입니다. 기본적으로 Scikit-Learn에서 제공하는 변환기가 많지만 우리가 필요한 모든 변환기가 구현되어 있진 않기때문에 필요에 따라 직접 원하는 변환기를 만들어야 할때가 있습니다.
이 포스트에서는 그 방법에 대해서 알아 보도록 하겠습니다.
우선 Scikit-Learn은 덕 타이핑duck typing을 지원하므로 fit(), transform(), fit_transform() 메서드를 구현한 파이썬 클래스를 만들면 됩니다. 여기에서 덕 타이핑이란 상속이나 인터페이스 구현이 아니라 객체의 속성이나 메서드가 객체의 유형을 결정하는 방식입니다. 마지막의 fit_transform()은 TransformerMixin으로 구현이 되어 있고 이를 상속하면 자동으로 생성됩니다.
또한 BaseEstimator를 상속하면 하이퍼파라미터 튜닝에 필요한 두 메서드 get_params()와 set_params()를 얻게 됩니다. 이때 생성자에 *args나 **kargs를 사용하지 않아야 합니다. 자세한 내용은 아래의 예시를 통해서 설명하겠습니다. 참고로 Scikit-Learn에 구현되어 있는 코드는 링크를 통해 확인해 볼 수 있습니다.
2. 예시
예시 코드는 Kaggle에서 제공하는 Titanic데이터를 활용하겠습니다. 이 글은 변환기를 만드는 방법에 대한 설명이라 전처리 방법은 간단한 방법으로 구현하여 올바른 방법이 아닐 수 있음을 말씁드립니다.
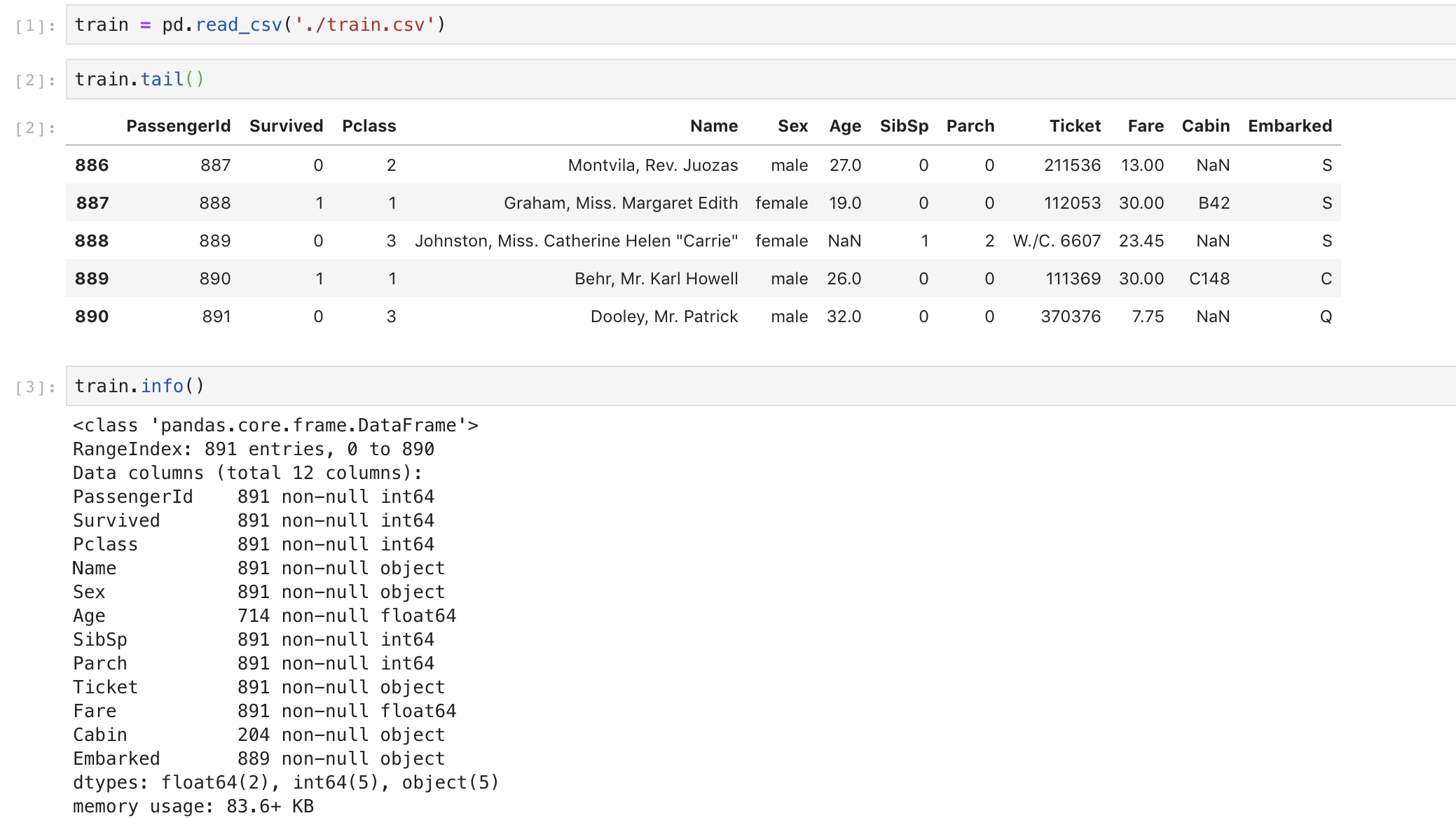 Titanic Data
Titanic Data
위 그림에서 데이터를 살펴보면 age에 NaN값이 존재함을 알 수 있습니다. NaN값을 처리하는 다양한 방법이 있지만 여기에서는 간단하게 모든 age값의 평균으로 채워 넣겠습니다.
위 코드와 같이 용도에 따라서 fit(), transform()을 만들어 주고 TransformerMix을 상속해주기만 하면 fit_transform()이 생성됩니다. 여러가지의 변환기를 연결시켜주는 Pipeline을 만들기 위해 name값을 first name만 표시하는 변환기를 만들어 보겠습니다.
이제 두 변환기를 Pipeline으로 연결하겠습니다.
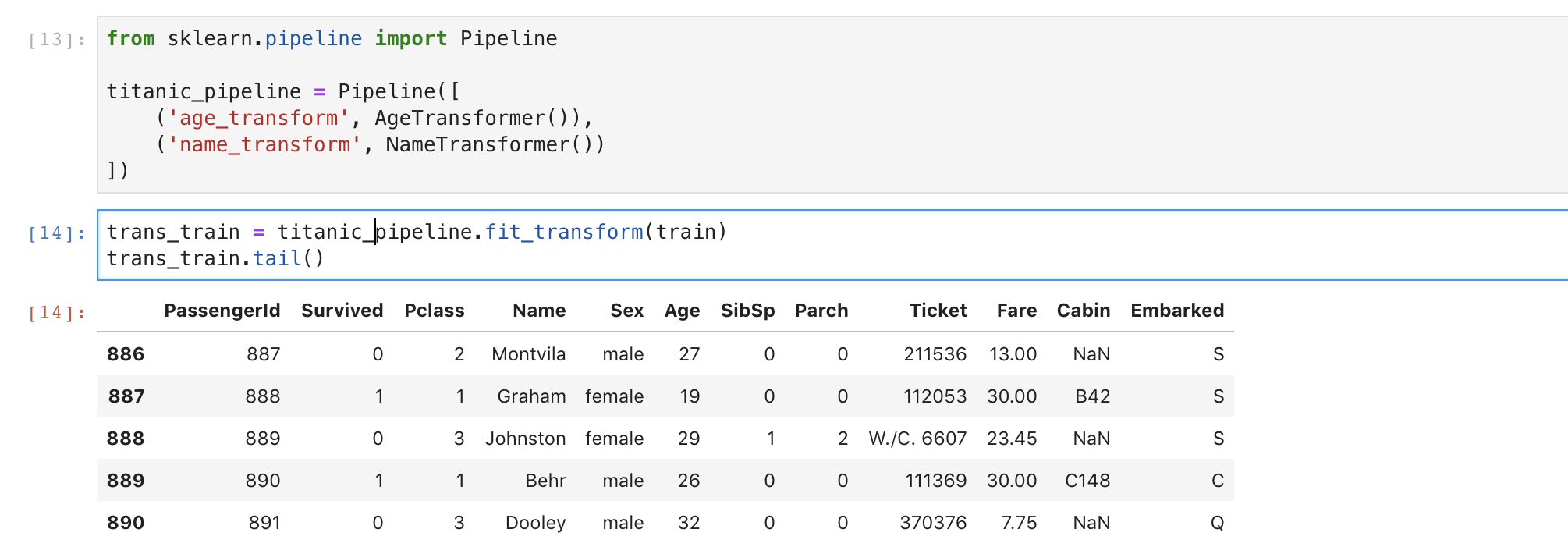 Pipeline
Pipeline
Pipeline으로 합쳐진 변환기의 결과를 보면 알 수 있듯이 위의 두 변환기를 각각 적용한 것을 하나의 pipeline으로 수행이 가능합니다. 이러한 방법으로 나만의 변환기를 만들어 사용할 수 있습니다.
3. 결론
위의 예시로 보았듯이 크게 어렵지 않게 변환기를 만들수 있었습니다. 사이킷런의 FeatureUnion을 사용하면 여러개의 pipeline을 하나의 pipeline으로 합칠 수도 있습니다. 하지만 아직 사이킷런의 pipeline에는 Pandas의 DataFrame을 직접 주입할 수 없고 결과도 array로 반환되기 때문에 이를 염두에 두고 만들어야 합니다. 필요에 따라서는 필요한 특성만을 선택하는 변환기를 따로 만들어야 하는 경우도 있습니다. 처음에는 어려울 수도 있지만 간단한 것부터 만들면서 원리를 익혀간다면 필요한 변환기를 만들 수 있을 것입니다.
※ 이 글의 내용은 Hands-On Machine Learning with Scikit-learn & TensorFlow 를 참고하여 작성하였습니다.
 HyunGeun Yoon
HyunGeun Yoon