
Machine Learning을 공부하였다면 한번쯤 XGBoost와 LightGBM, H2O를 들어보았을 것이다. 최근 이 분야에서 기존의 기술들을 위협하는 새로운 기술이 나와 이를 소개하고자 한다.
이 글은 참고블로그 (Towards Data Science)와 참고기사의 내용을 번역 및 요약 정리하였고 좀 더 자세한 내용은 링크를 통해 확인해볼 수 있다.
Catboost란 무엇인가?
Catboost란 Yandex에서 개발된 오픈 소스 Machine Learning이다. 이 기술은 다양한 데이터 형태를 활용하여 기업이 직면한 문제들을 해결하는데 도움을 준다. 특히 분류 정확성에서 높은 점수를 제공한다.
Catboost는 Category와 Boosting을 합쳐서 만들어진 이름이다.
여기에서 Boost는 Gradient boosting machine learnin algorithm에서 온 말인데 Gradient boosting은 추천 시스템, 예측 등 다양한 분야에서 활용되어지는 강력한 방법이고 Deep Learning과 달리 적은 데이터로도 좋은 결과를 얻을 수 있는 효율적인 방법이다.
왜 Catboost를 활용하는가?
더 좋은 결과
Catboost는 Benchmark에서 더 좋은 결과를 얻었다.
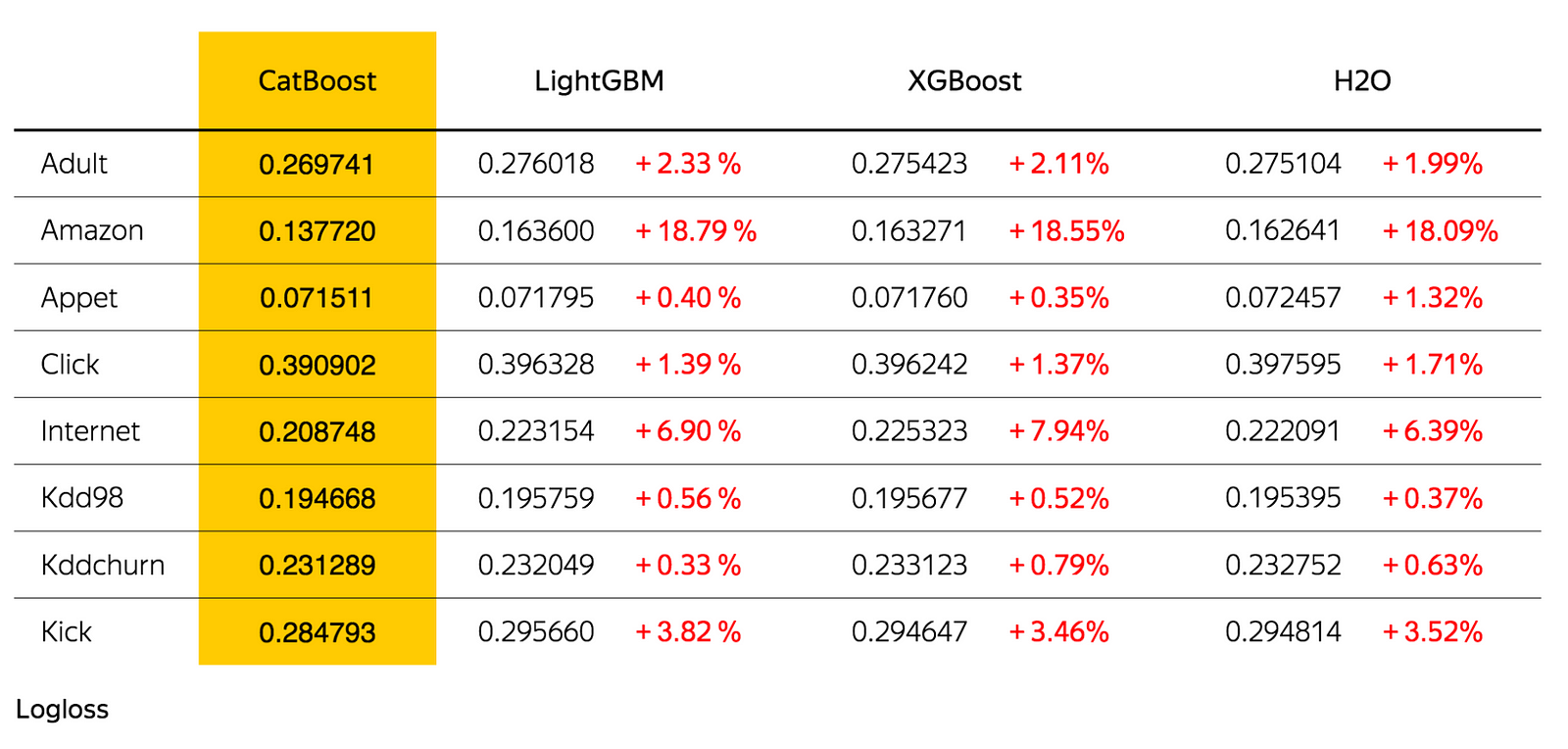
Category features 사용의 편리성
Category features를 사용하기 위해서는 One-Hot-Encoding등 데이터를 전처리할 필요가 있었지만 Catboost에서는 사용자가 다른 작업을 하지 않아도 자동으로 이를 변환하여 사용한다. 이 분야를 공부한 경험이 있다면 이 기능이 얼마나 편리한지를 알 수 있을 것이다. 자세한 내용은 document를 통해 확인할 수 있다.
빠른 예측
학습 시간이 다른 GBDT에 보다는 더 오래 걸리는 대신에 예측 시간이 13-16배 정도 더 빠르다.
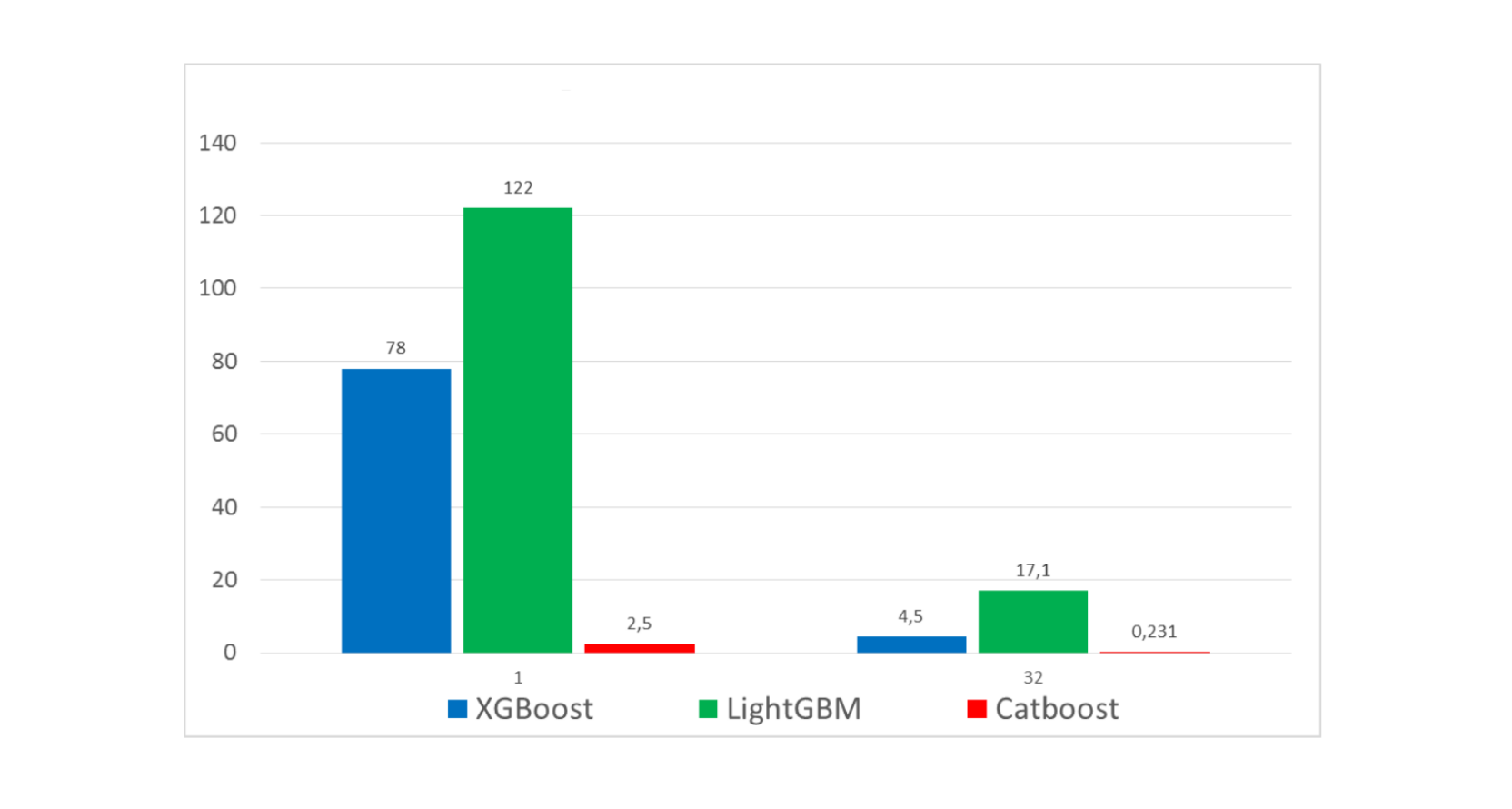
더 나은 기능들
- default parameters값으로 더 나은 성능
hyper-parmeter tuning을 하지 않더라도 기본적인 세팅으로도 좋은 결과를 얻을 수 있어 활용성이 뛰어나다. 자세한 내용은 document를 통해 확인할 수 있다.

- feature interactions
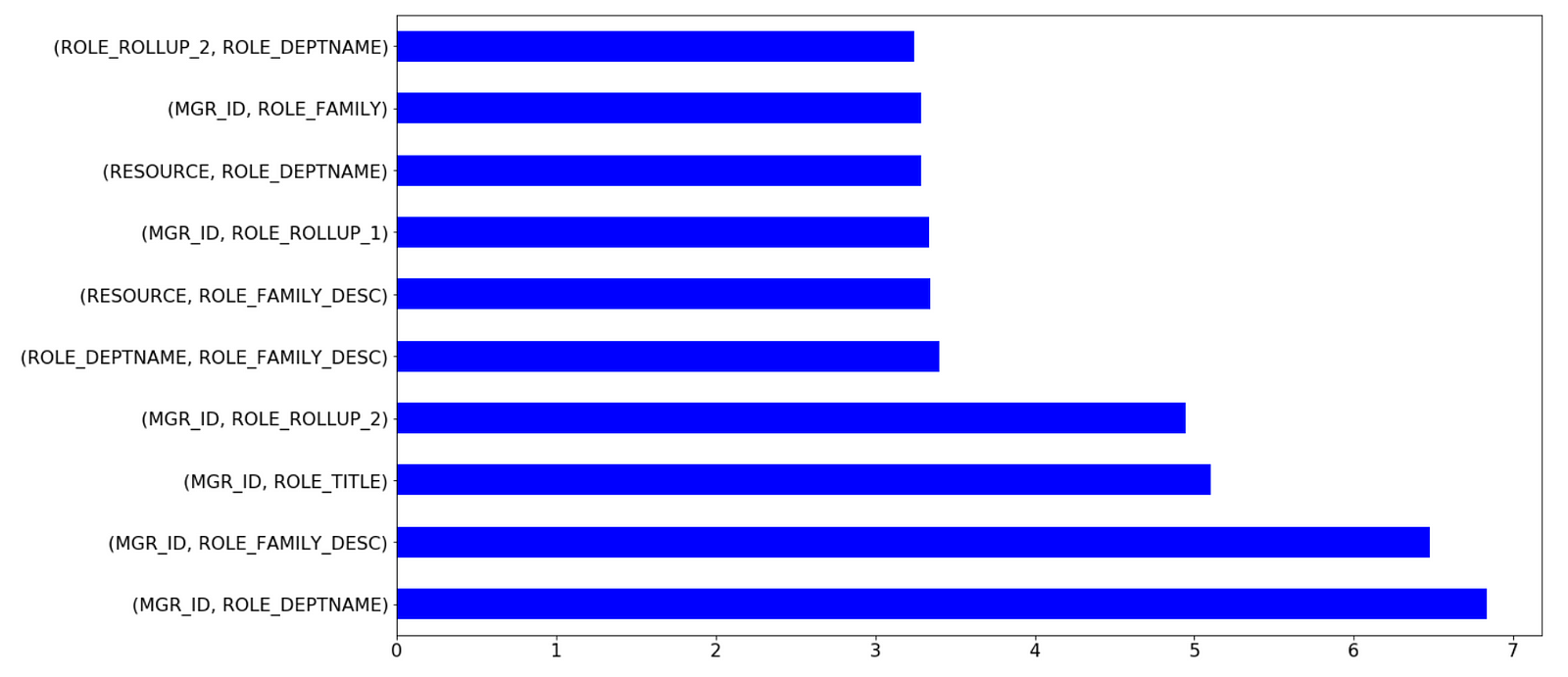
- feature importances
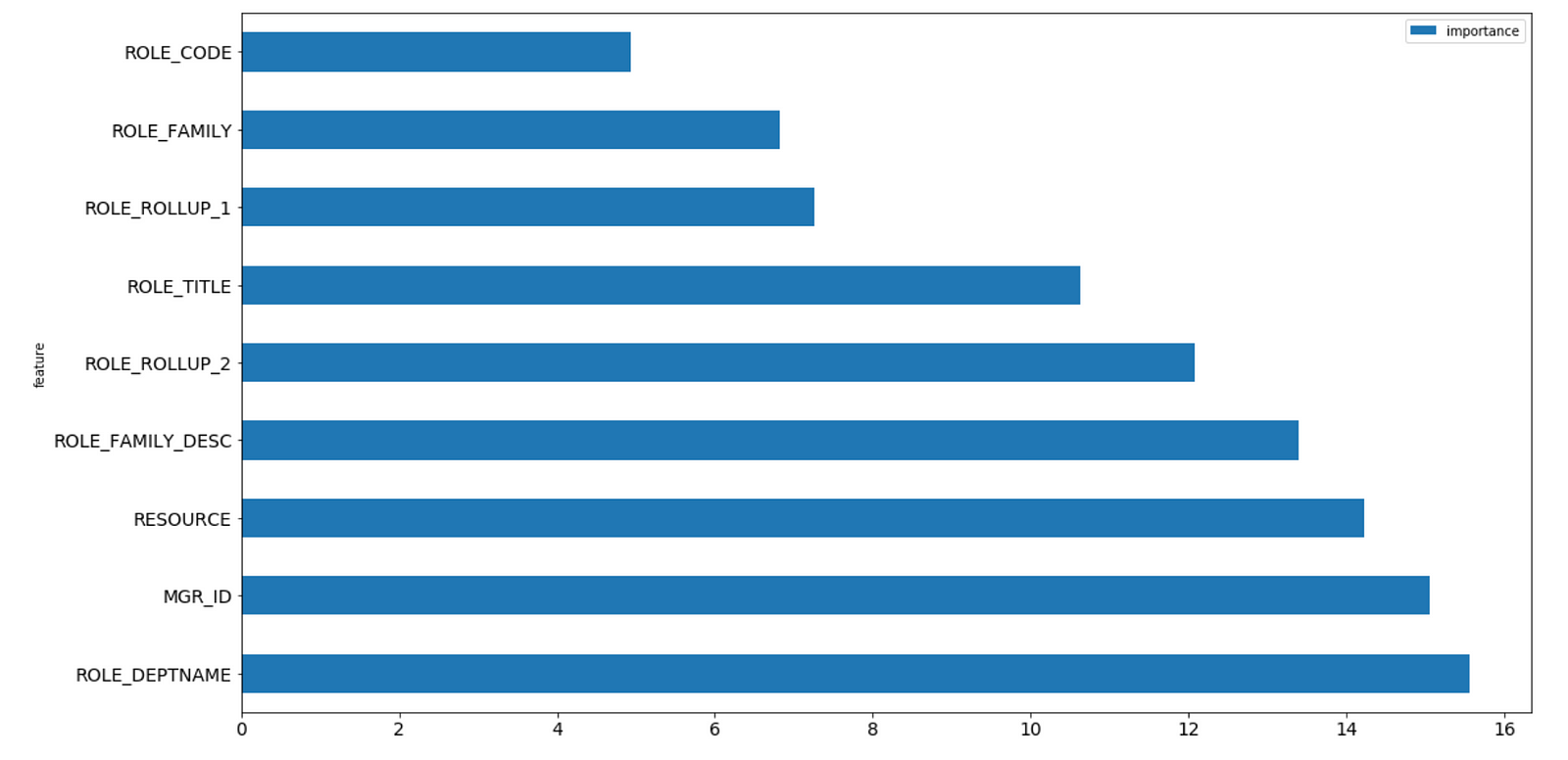
- object(row) importances
- the snapshot
결론
프로젝트 등을 수행하다보면 Catgory feature를 이용하는 것이 상당히 번거롭다는 것을 알 수 있을 것이다. 뿐만 아니라 예측 시간이 오래걸린다면 실제로 시스템에 적용하는데는 큰 문제점을 가지고 있음을 알고 있다.
다른 Maching Learning algorithms의 단점을 보완해주는 Catboost를 잘 활용한다면 좀 더 나은 시스템을 개발하는데 도움이 될 것이다.
 HyunGeun Yoon
HyunGeun Yoon